Decision Tree Pruning
Decision Tree Pruning: Practical issues while building a decision tree can be enumerated as follows:
1) How deep should the tree be?
2) How do we handle continuous attributes?
3) What is a good splitting function?
4) What happens when attribute values are missing?
5) How do we improve the computational efficiency
The depth of the tree is related to the generalization capability of the tree. If not carefully chosen it may lead to overfitting. A tree overfits the data if we let it grow deep enough so that it begins to capture “aberrations” in the data that harm the predictive power on unseen examples:
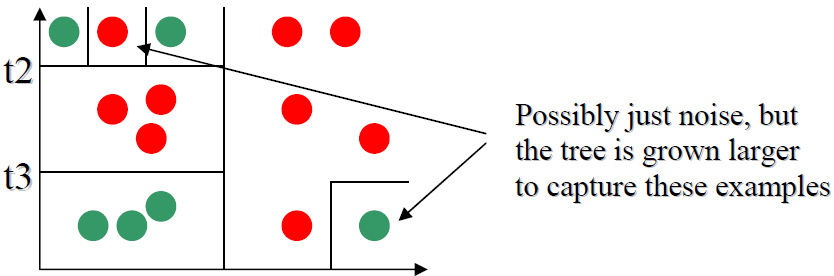
There are two main solutions to overfitting in a decision tree:
1. Stop the Tree early before it begins to overfit the data. In practice this solution is hard to implement because it is not clear what is good stopping point.
2. Grow the tree until the algorithm stops even if the overfitting problem shows up.
Then prune the tree as a post-processing step.
This method has found great popularity in the machine learning community.
A common decision tree pruning algorithm is described below.
- Consider all internal nodes in the tree.
- For each node check if removing it (along with the subtree below it) and assigning the most common class to it does not harm accuracy on the validation set.
- Pick the node n* that yields the best performance and prune its subtree.
- Go back to (2) until no more improvements are possible.
Decision trees are appropriate for problems where:
- Attributes are both numeric and nominal.
- Target function takes on a discrete number of values.
- A DNF representation is effective in representing the target concept.
- Data may have errors.