Learning Issues
Learning is the ability of an agent to improve its behavior based on experience. This could mean the following:
- The range of behaviors is expanded; the agent can do more.
- The accuracy on tasks is improved; the agent can do things better.
- The speed is improved; the agent can do things faster.
The ability to learn is essential to any intelligent agent. As Euripides pointed, learning involves an agent remembering its past in a way that is useful for its future. This chapter considers supervised learning: given a set of training examples made up of input-output pairs, predict the output of a new input. We show how such learning may be based on one of four possible approaches: choosing a single hypothesis that fits the training examples well, predicting directly from the training examples, selecting the subset of a hypothesis space consistent with the training examples, or finding the posterior probability distribution of hypotheses conditioned on the training examples.
The following components are part of any learning problem:
- task: The behavior or task that is being improved
- data: The experiences that are used to improve performance in the task measure of improvement How the improvement is measured - for example, new skills that were not present initially, increasing accuracy in prediction, or improved speed
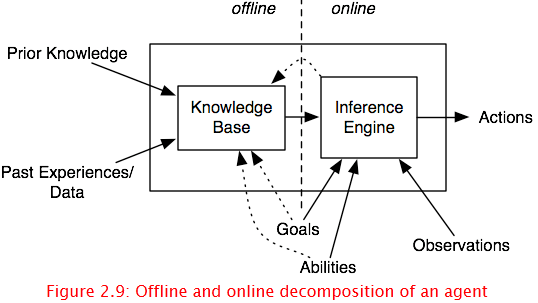
Consider the agent internals of Figure 2.9. The problem of learning to take in prior knowledge and data (e.g., about the experiences of the agent) and to create an internal representation (the knowledge base) that is used by the agent as it acts. This internal representation could be the raw experiences themselves, but it is typically a compact representation that summarizes the data. The problem of inferring an internal representation based on examples is often called induction can be contrasted with deduction, which is deriving consequences of a knowledge base, and abduction, which is hypothesizing what may be true about a particular case.
There are two principles that are at odds in choosing a representation scheme:
- The richer the representation scheme, the more useful it is for subsequent problems solving. For an agent to learn a way to solve a problem, the representation must be rich enough to express a way to solve the problem.
- The richer the representation, the more difficult it is to learn. A very rich representation is difficult to learn because it requires a great deal of data, and often many different hypotheses are consistent with the data.
The representations required for intelligence are a compromise between many desiderata. The ability to learn the representation is one of them, but it is not the only one.
Learning techniques face the following issues:
- Task
-
Virtually any task for which an agent can get data or experiences can be learned. The most commonly studied learning task is supervised learning given some input features, some target features, and a set of training examples the input features and the target features are specified, predict the target features of a new example for which the input features are given. This is called classification the target variables are discrete and regression the target features are continuous.
Other learning tasks include learning classifications when the examples are not already classified (unsupervised learning), learning what to do based on rewards and punishments (reinforcement learning), learning to reason faster (analytic learning), and learning richer representations such as logic programs (inductive logic programming) or Bayesian networks.
- Feedback
- Learning tasks can be characterized by the feedback given to the learner. In supervised learning what has to be learned is specified for each example. Supervised classification occurs when a trainer provides the classification for each example. Supervised learning of actions occurs when the agent is given immediate feedback about the value of each action. Unsupervised learning when no classifications are given and the learner must discover categories and regularities in the data. Feedback often falls between these extremes, such as in reinforcement learning where the feedback in terms of rewards and punishments occurs after a sequence of actions. This leads to the credit-assignment problem determining which actions were responsible for the rewards or punishments. For example, a user could give rewards to the delivery robot without telling it exactly what it is being rewarded for. The robot then must either learn what it is being rewarded for or learn which actions are preferred in which situations. It is possible that it can learn what actions to perform without actually determining which consequences of the actions are responsible for rewards.