Graph Indexing With Discriminative Frequent Substructures
Introduction: Indexing is essential for efficient search and query processing in database and information systems. Technology has evolved from single-dimensional to multidimensional indexing, claiming a broad spectrum of successful applications, including relational database systems and spatiotemporal, time-series, multimedia, text-, and Web-based information systems. However, the traditional indexing approach encounters challenges in databases involving complex objects, like graphs, because a graph may contain an exponential number of sub-graphs. It is ineffective to build an index based on vertices or edges, because such features are nonselective and unable to distinguish graphs. On the other hand, building index structures based on sub-graphs may lead to an explosive number of index entries.
Recent studies on graph indexing have proposed a path-based indexing approach, which takes the path as the basic indexing unit. This approach is used in the Graph Grep and Daylight systems. The general idea is to enumerate all of the existing paths in a database up to maxL length and index them, where a path is a vertex sequence, v1;v2; : : : ;vk, such that, 81 ≤ i ≤ k-1, (vi;vi 1) is an edge. The method uses the index to identify every graph, gi, that contains all of the paths (up to maxL length) in query q. Even though paths are easier to manipulate than trees and graphs, and the index space is predefined, the path-based approach may not be suitable for complex graph queries, because the set of paths in a graph database is usually huge. The structural information in the graph is lost when a query graph is broken apart. It is likely that many false-positive answers will be returned. This can be seen from the following example.
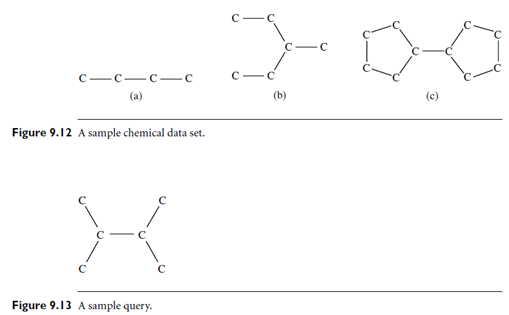
Example: Difficulty with the path-based indexing approach. Figure 9.12 is a sample chemical data set extracted from an AIDS antiviral screening database. For simplicity, we ignore the bond type. Figure 9.13 shows a sample query: 2, 3-dimethylbutane. Assume that this query is posed to the sample database. Although only graph (c) in Figure 9.12 is the answer, graphs (a) and (b) cannot be pruned because both of them contain all of the paths existing in the query graph: c, c-c, c-c-c, and c-c-c-c. In this case, carbon chains (up to length 3) are not discriminative enough to distinguish the sample graphs. This indicates that the path may not be a good structure to serve as an index feature.
A method called gIndex was developed to build a compact and effective graph index structure. It takes frequent and discriminative substructures as index features. Frequent substructures are ideal candidates because they explore the shared structures in the data and are relatively stable to database updates. To reduce the index size (i.e., the number of frequent substructures that are used in the indices), the concept of discriminative frequent substructure is introduced. A frequent substructure is discriminative if its support cannot be well approximated by the intersection of the graph sets that contain one of its sub-graphs. The experiments on the AIDS antiviral data sets and others show that this method leads to far smaller index structures. In addition, it achieves similar performance in comparison with the other indexing methods, such as the path index and the index built directly on frequent substructures.