Text Data Analysis And Information Retrieval
Introduction: Information retrieval (IR) is a field that has been developing in parallel with database systems for many years. Unlike the field of database systems, which has focused on query and transaction processing of structured data, information retrieval is concerned with the organization and retrieval of information from a large number of text-based documents. Since information retrieval and database systems each handle different kinds of data, some database system problems are usually not present in information retrieval systems, such as concurrency control, recovery, transaction management, and update. Also, some common information retrieval problems are usually not encountered in traditional database systems, such as unstructured documents, approximate search based on keywords, and the notion of relevance.
Due to the abundance of text information, information retrieval has found many applications. There exist many information retrieval systems, such as on-line library catalog systems, on-line document management systems, and the more recently developed Web search engines.
A typical information retrieval problem is to locate relevant documents in a document collection based on a user’s query, which is often some keywords describing an information need, although it could also be an example relevant document. In such a search problem, a user takes the initiative to “pull” the relevant information out from the collection; this is most appropriate when a user has some ad hoc (i.e., short-term) information need, such as finding information to buy a used car. When a user has a long-term information need (e.g., a researcher’s interests), a retrieval system may also take the initiative to “push” any newly arrived information item to a user if the item is judged as being relevant to the user’s information need. Such an information access process is called information filtering, and the corresponding systems are often called filtering systems or recommender systems. From a technical viewpoint, however, search and filtering share many common techniques. Below we briefly discuss the major techniques in information retrieval with a focus on search techniques.
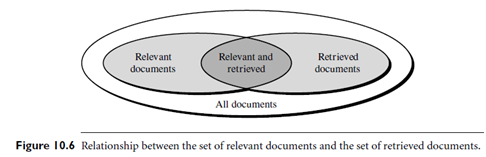
Basic Measures for Text Retrieval: Precision and Recall: “Suppose that a text retrieval system has just retrieved a number of documents for me basedon my input in the form of a query. How can we assess how accurate or correct the systemwas?” Let the set of documents relevant to a query be denoted as {Relevant}, and the setof documents retrieved be denoted as {Retrieved}. The set of documents that are bothrelevant and retrieved is denoted as {Relevant} \ {Retrieved}, as shown in the Venndiagram of Figure 10.6. There are two basic measures for assessing the quality of textretrieval:
Precision: This is the percentage of retrieved documents that are in fact relevant to the query (i.e., “correct” responses). It is formally defined as
Precision = |{Relevant}∩{Retrieved}|/ |{Retrieved}|
Recall: This is the percentage of documents that are relevant to the query and were, in fact, retrieved. It is formally defined as
Recall = |{Relevant}∩{Retrieved}|/ |{Retrieved}|
An information retrieval system often needs to trade off recall for precision or vice versa. One commonly used trade-off is the F-score, which is defined as the harmonic mean of recall and precision:
F_score = recall X precision / {(recall precision)/2}
 The harmonic mean discourages a system that sacrifices one measure for another too drastically.
The harmonic mean discourages a system that sacrifices one measure for another too drastically.
Precision, recall, and F-score are the basic measures of a retrieved set of documents. These three measures are not directly useful for comparing two ranked lists of documents because they are not sensitive to the internal ranking of the documents in a retrieved set. In order to measure the quality of a ranked list of documents, it is common to compute an average of precisions at all the ranks where a new relevant document is returned. It is also common to plot a graph of precisions at many different levels of recall; a higher curve represents a better-quality information retrieval system.