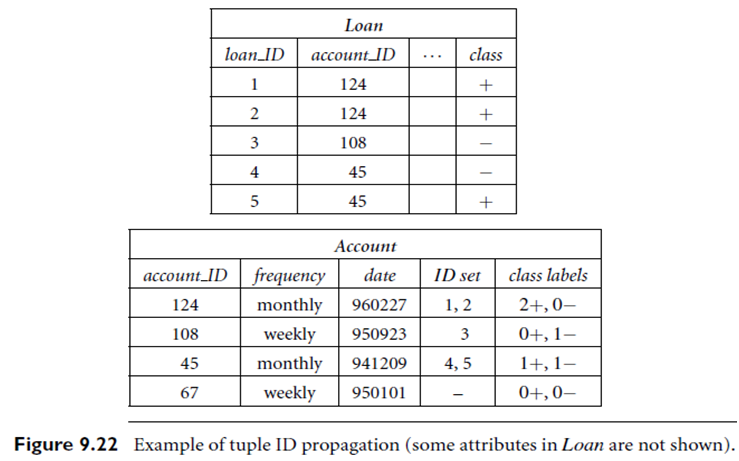
Tuple Id Propagation
Introduction: Tuple ID propagation is a technique for performing virtual join, which greatly improves efficiency of multi-relational classification. Instead of physically joining relations, they are virtually joined by attaching the IDs of target tuples to tuples in non target relations. In this way the predicates can be evaluated as if a physical join were performed.
Tuple ID propagation is flexible and efficient, because IDs can easily be propagated between any two relations, requiring only small amounts of data transfer and extra storage space. By doing so, predicates in different relations can be evaluated with little redundant computation.
Suppose that the primary key of the target relation is an attribute of integers, which represents the ID of each target tuple (we can create such a primary key if there isn’t one). Suppose two relations, R1 and R2, can be joined by attributes R1:A and R2:A. In tuple ID propagation, each tuple t in R1 is associated with a set of IDs in the target relation, represented by ID set(t). For each tuple u in R2, we set IDset(u)= 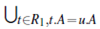 IDset(t). That is, the tuple IDs in the IDset for tuple t of R1 are propagated to each tuple, u, in R2 that is joinable with t on attribute A.
IDset(t). That is, the tuple IDs in the IDset for tuple t of R1 are propagated to each tuple, u, in R2 that is joinable with t on attribute A.