Elman Networks
Introduction:-The Elman networks have context neurons, too, but one layer of context neurons per information processing neuron layer. Thus, the outputs of each hidden neuron or output neuron are led into the associated context layer (again exactly one context neuron per neuron) and from there it is reentered into the complete neuron layer during the next time step (i.e. again a complete link on the way back). So the complete information processing part1 of the MLP exists a second time as a "context version" – which once again considerably increases dynamics and state variety. Compared with Jordan networks the Elman networks often have the advantage to act more purposeful since every layer can access its own context.
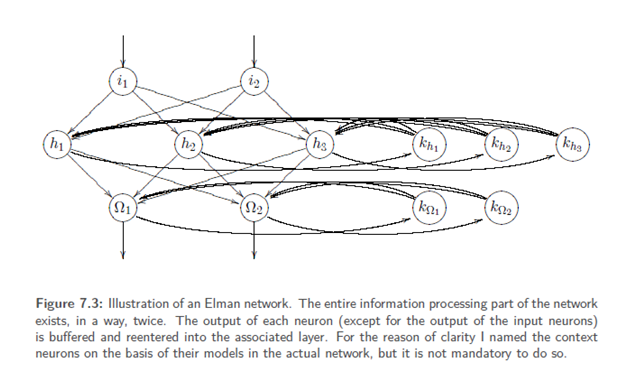
An Elman network is an MLP with one context neuron per information processing neuron. The set of context neurons is called K. This means that there exists one context layer per information processingneuron layer with exactly the same numberof context neurons. Every neuron hasa weighted connection to exactly one contextneuron while the context layer is completely linked towards its original layer. Now it is interesting to take a look at thetraining of recurrent networks since, for instance, ordinary back propagation of error cannot work on recurrent networks.