Fuzzy Logic Model For Speech Recognition And Languageunderstanding
Introduction:-This model is based on the assumption that the whole process of speech recognition and language analysis is an integrated continuous process and the border between the two is not well-defined.
This process can be viewed in two dimensions time and type of knowledge applied in order to recognize and understand a spoken sequence, where the speech recognition and language analysis phases overlap in both dimensions. For example, correctly recognizing a spoken phoneme may require understanding the context of the whole word, and also some words pronounced before and after it.
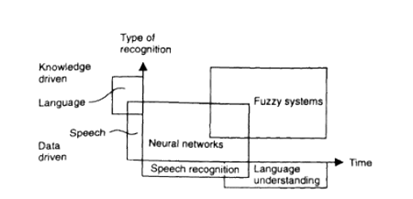
Figure represents the applicability of neural networks and fuzzy systems to solving different subtasks from the speech recognition and language understanding processes represented in the two dimensions: "time" and "type of recognition.
It has the following main modules:
- Preprocessing module. This performs nonlinear transformations over the raw speech signal and extracts features. Different standard transformations could be applied.
- A neural network module for low-level, phoneme recognition. This can be a single neural network or a multi network structure of many specialized neural networks for recognizing patterns of sub-units, for example parts of phonemes or phonemes. Different types of networks can be used. This module is adaptable and trainable with speech samples of phonemes from a speech corpus.
- A higher-level fuzzy rule-based system performs approximate reasoning over fuzzy rules for phoneme, words, sentence, concept, and meaning recognition. The higher level is, in general, a multilayer structure of fuzzy rules which represent different layers of speech and language knowledge.It can be a simple flat fuzzy rules system or a quite complicated system, depending on the task.
For example, the fuzzy system realizes linguistic rules from a set of linguistic knowledge, forms words and matches the recognized words into a pre-defined dictionary.
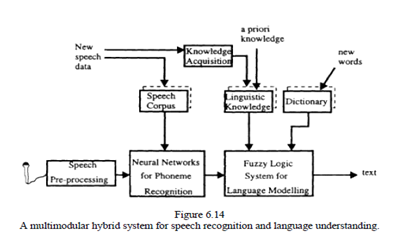
The following principles are used when building a concrete speech recognition system based on the model of figure 6.14:
- The principle of hierarchy. The speech elements are recognized through their natural hierarchy of subunits, units, strings.
- The principle of a delayed decision. A lower-level decision is temporarily accepted for further processing, but is subject to correction due to the higher-level knowledge available and the interaction between the levels in the system.
- The principle of the fuzzy winner. At each level, not one, but many possible subunits and units are kept for further processing and not just the one winning at that moment.
- he principle of making use of both data and knowledge when building a speech recognition system. This principle means also applying both "unconscious," "blind," or "stimulus-reaction “recognition, and "conscious," rule-based or directed, recognition.
The principle of adaptability:-A system based on the model is adaptable to new variations of speech, new vocabularies, etc. The adaptability is achieved in three ways: (1) additional training of the neural networks at the lower level with examples of new speech variations; (2) adding or changing fuzzy rules in the higher-level module for representing the new speech characteristics; (3) learning fuzzy rules from new speech data and adding these rules to the already existing ones for higher-level processing.