Growing Rbf Networks Automatically Adjust The Neuron Density
Introduction:-In growing RBF networks, the number |H| of RBF neurons is not constant. A certain number |H| of neurons as well as their centers ch and widths σhare previously selected (e.g. by means of a clustering method) and then extended or reduced.
Neurons are added to places with large error values:-After generating this initial configuration the vector of the weights G is analytically calculated. Then all specific errors Errpconcerning the set P of the training samples are calculated and the maximum specific error 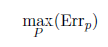 is sought.
is sought.
The extension of the network is simple: We replace this maximum error with a new RBF neuron. Of course, we have to exercisecare in doing this: IF the σ are small,the neurons will only influence each otherif the distance between them is short. Butif the σare large, the already existing neurons are considerably influenced by thenew neuron because of the overlapping ofthe Gaussian bells.So it is obvious that we will adjust the alreadyexisting RBF neurons when addingthe new neuron.To put it simply, this adjustment is madeby moving the centers c of the other neuronsaway from the new neuron and reducingtheir width σ a bit. Then thecurrent output vector y of the network iscompared to the teaching input t and theweight vector G is improved by means oftraining. Subsequently, a new neuron canbe inserted if necessary. This method is particularly suited for function approximations.
Limiting the number of neurons:-Here it is mandatory to see that the networkwill not grow ad infinitum, which canhappen very fast. Thus, it is very useful to previously define a maximum number for neurons |H|max.
Less important neurons are deleted:-Which leads to the question whether I tis possible to continue learning when thislimit |H|max is reached. The answer is: this would not stop learning. We only haveto look for the "most unimportant" neuronand delete it. A neuron is, for example, unimportant for the network if there is another neuron that has a similar function:It often occurs that two Gaussian bells exactlyoverlap and at such a position, for instance, one single neuron with a higher Gaussian bell would be appropriate. But to develop automated procedures in order to find less relevant neurons is highly problem dependent and we wantto leavethis to the programmer. With RBF networks and multilayer perceptrons we have already become acquainted with and extensively discussedtwo network paradigms for similar problems. Therefore we want to compare thesetwo paradigms and look at their advantagesand disadvantages.