Mlp For Speech Recognition
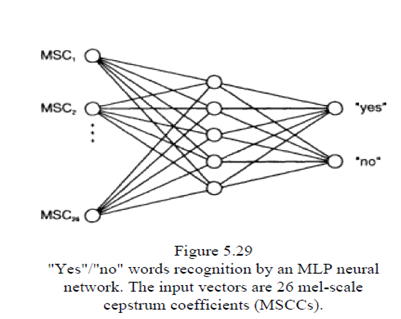
A "yes"/"no" whole-word recognition MLP is shown below. It has 26 input nodes for the 26 Mel-scale coefficients, which in this case are averaged over several segments, to cover the whole words. The two words' speech signals are transformed into 26-element vectors. Samples of" yes"/ "no" spoken words are collected from different speakers-male, female, various age groups, etc. The network is trained and then tested on newly pronounced "yes''/"no" words. If the test words are pronounced by one of the speakers whose spoken words were used for training, and the system recognizes them, then the system is said to be of a multiple-speaker type. If the system recognizes a new speaker, then the system is called speaker independent.
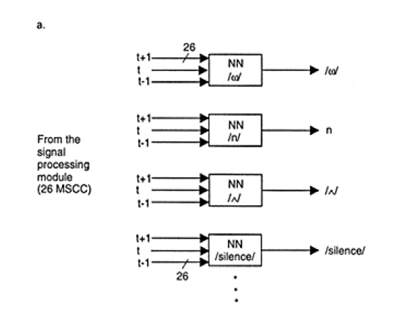
Phoneme recognition is a difficult problem because of the variation in the pronunciation of phonemes, the time alignment problem (the phonemes are not pronounced in and because of what is called the coarticulation effect, that is, the frequency characteristics of an allophonic realization of the same phoneme may differ depending on the context of the phoneme in different spoken.
TThere are two approaches to using MLP for the task of phoneme recognition:
(1) using one, big MLP,which has as its outputs all the possible phonemes, and
(2) using many small networks, specialized to recognize from one to a small group of phonemes (e.g., vowels, consonants, fricatives, plosives, etc.).
A multimodular neural network architecture for recognizing several phonemes-/w/, /Ù/, /n/, /silence/—is shown in figure .One 78-10-1 MLP network is trained for each of the phonemes. The outputs of these networks need to be monitored, the winner being chosen for any time segment of 11.6 ms.