Using Som For Phoneme Recognition
The feature vectors obtained after signal processing e.g. the Mel-scale cepstrum coefficients vectors, can be used as training examples for training a SOM. Vectors representing allophonic realizations of the same phoneme are taken from different windows (frames) over one signal sample and from different signals, that is, different realizations of this phoneme. After enough training, every phoneme is represented on the SOM by the activation of some output nodes. One node fires when an input vector representing a segment of the allophonic realization of this phoneme is fed into the network. The outputs, which react to the same phoneme pronounced differently, are positioned closely. The outputs that react to similar phonemes are positioned in proximity on the map. This is due to the ability of the SOM to activate topologically close output neurons when similar input vectors are presented.
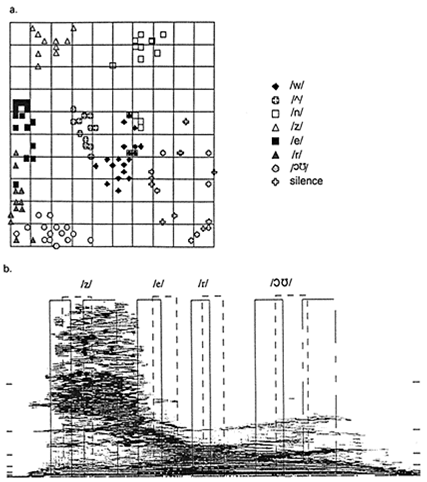 This approach has been used and phonemic maps have been created for Finnish, Japanese, English, Bulgarian (and other languages. Figure A is a two-dimensional drawing of the coordinates of the neurons in a SOM that was labeled with eight phonemes in English selected from digits pronounced by a small group of speakers. Figure B shows how allophonic segments of phonemes were segmented for training the SOM. It is clear from this drawing that the phonemes are well distinguished, and there are areas where the network cannot produce any meaningful classification. Instead of having a large, and therefore slow-to-process single SOM, hierarchical models of SOMs can be used.
This approach has been used and phonemic maps have been created for Finnish, Japanese, English, Bulgarian (and other languages. Figure A is a two-dimensional drawing of the coordinates of the neurons in a SOM that was labeled with eight phonemes in English selected from digits pronounced by a small group of speakers. Figure B shows how allophonic segments of phonemes were segmented for training the SOM. It is clear from this drawing that the phonemes are well distinguished, and there are areas where the network cannot produce any meaningful classification. Instead of having a large, and therefore slow-to-process single SOM, hierarchical models of SOMs can be used.
Every SOM at the second level is activated when a corresponding neuron from the first level becomes active. The asymptotic computational complexity of the recognition of the two-level hierarchical model is 0(2 × n × m) where n is the number of inputs and m is the size of a single SOM. This is much less than the computational complexity O(n · m2) of a single SOM with a size of m2 (m = 16). For a general r-level hierarchical model, the complexity is O(r · n · m). The first-level SOM is trained to recognize four classes of phonemes: a pause, a vocalized phoneme, a no vocalized phoneme, and a fricative segment.
The network is trained with three features of the speech signal:
(1) The mean value of the energy of the time-scale signal within the segment;
(2) The number of the crossings of zero for the time-scale signal; and
(3) The mean value of the local extremes of the amplitude of the signal on the time scale.