Usage Patterns And Platform Constraints
Usage Patterns and Platform Constraints: It is worthwhile to first examine the usage patterns of GPUs in general purpose applications as well as the constraints
imposed by hardware and software architectures before developing any real-time analysis approach. As we shall see, these real-world characteristics cannot be ignored in a holistic system point-of-view. We begin by examining GPU execution environments.
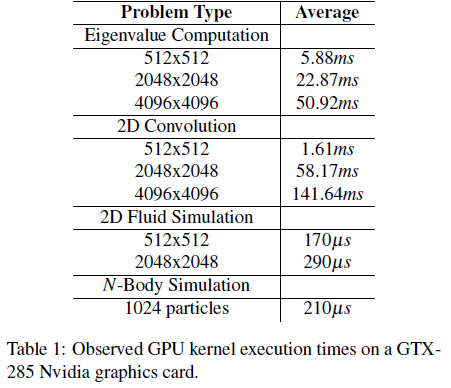
The execution time of a GPU program, called a kernel, varies from application to application and can be relatively long. To determine likely execution-time ranges, we profiled sample programs from Nvidia’s CUDA SDK on a GTX-285 Nvidia graphics card. We found that n-body simulations run on the order of 10–100ms per iteration on average while problems involving large matrix calculations (multiplication, eigenvalues, etc.) can take 10–200ms on average. Table 1 contains a summary of observed GPU execution times for several basic operations.
The results in Table 1 indicate that relatively long GPU access times are common. Additionally, the I/O-based interface to a GPU co-processor introduces several additional unique constraints that need to be considered. First, a GPU cannot access main memory directly, thus making the memory between the host and GPU non-coherent between synchronization points. Memory is transferred over the bus (PCIe) explicitly or through automated DMA to explicitly-allocated blocks of main memory (in integrated graphics solutions, the GPU uses a partitioned section of main memory, but the architectural abstractions remain). Second, kernel execution on a GPU is non-preemptive: execution of the kernel must be run to completion before another kernel may begin. Third, kernels may not execute concurrently on a GPU even if many of the GPU’s parallel sub-processors are unused. Finally, a GPU is not a system programmable device in the sense that a general OS cannot schedule or otherwise control a GPU. Instead, a driver in the OS manages the GPU. This last constraint bears additional explanation.
At runtime, the host-side program sends data to the GPU, invokes a GPU program, and then waits for results. While this model looks much like a remote procedure call, unlike a remote RPC-accessible system, the GPU is unable to schedule its own workloads. Instead, the host-side driver manages all data transfers to and from the device, triggers kernel invocations, and handles the associated interrupts. Furthermore, this driver is closed-source since the vendor is unwilling to disclose proprietary information regarding the internal operations of the GPU. Also, driver properties may change from vendor to vendor, GPU to GPU, and even from driver version to version. Since even soft real-time systems require provable analysis, the uncertain behaviors of the driver force integration solutions to treat it as a black box.
Unknown driver behaviors are not merely speculative but are a real concern. For example, we found that a recent Nvidia CUDA driver may induce uncontrollable busywaiting when the GPU is under contention, despite all runtime environment controls to the contrary. Further complicating matters, the driver does not provide predictable real-time synchronization, an issue that receives more attention in Sec. 4.1.