Information Processing Of An Rbf Network
Introduction:-An RBF network receives the input by means of the unweight connections. Then the input vector is sent through a norm so that the result is a scalar. This scalar is processed by a radial basis function.
The output values of the different neurons n of the RBF layer or of the different Gaussianbells are added within the third layer basically, in relation to the whole inputspace, Gaussian bells are added here.
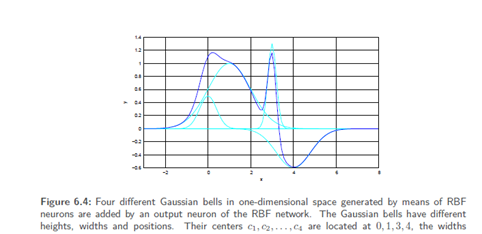
Suppose that we have a second, a thirdand a fourth RBF neuron and thereforefour differently located centers. Each of these neurons now measures another distancefrom the input to its own centerand de facto provides different values, evenif the Gaussian bell is the same. Since these values are finally simply accumulatedin the output layer, one can easilysee that any surface can be shaped by dragging, compressing and removing Gaussianbells and subsequently accumulating them. Here, the parameters for the superposition of the Gaussian bells are in the weights of the connections between the RBF layer and the output layer.
Furthermore, the network architecture offers the possibility to freely define or train height and width of the Gaussian bells –due to which the network paradigm becomes even more versatile. We will get to know methods and approaches for this later.
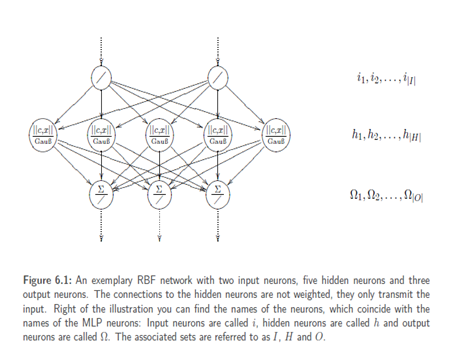
Information processing in RBF neurons
RBF neurons process information by using norms and radial basis functions. At first, let us take as an example a simple1-4-1 RBF network. It is apparentthat we will receive a one-dimensional outputwhich can be represented as a function. Additionally, the network includes the centersc1, c2. . . c4 of the four inner neuronsh1, h2, . . . , h4, and therefore it has Gaussianbells which are finally added withinthe output neuron Ω . The network alsopossesses four values whichinfluence the width of the Gaussian bells. On the contrary, the height of the Gaussianbell is influenced by the subsequentweights, since the individual output valuesof the bells are multiplied by those weights.
Since we use a norm to calculate the distance between the input vector and the center of a neuron h, we have different choices: Often the Euclidian norm is chosen to calculate the distance:
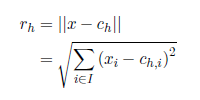
The input vector was referred to as x. Here, the index i runs through the input neurons and thereby through theinput vector components and the neuron center components. As we can see, the Euclidean distance generates the squared differences of all vector components, adds them and extracts the root of the sum. In two-dimensional space this corresponds to the Pythagorean Theorem. From the definitionof a norm directly follows that the distance can only be positive. Strictly speaking, we hence only use the positive part of the activation function. By the way, activation functions other than the Gaussian bell are possible. Normally, functions that are monotonically decreasing over the interval [0;1] are chosen. Now that we know the distance rh between the input vector x and the center ch of the RBF neuron h, this distance has to be passed through the activation function.
Here we use, as already mentioned,a Gaussian bell:
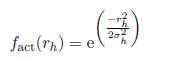
It is obvious that both the center ch and the width σh can be seen as part of theactivation function fact, and hence the activation functions should not be referred to as fact simultaneously. One solution would be to number the activation functions like fact1, fact2, . . . ,fact|H|with H being the set of hidden neurons. But as a result the explanation would be very confusing. So we simply use the name fact for all activation functions and regard σandc as variables that are defined for individual neuronsbut no directly included in the activation function.
The reader will certainly notice that in the literature the Gaussian bell is often normalized by a multiplicative factor. We can, however, avoid this factor because we are multiplying anyway with the subsequent weights and consecutive multiplications, first by a normalization factor andthen by the connections’ weights, would only yield different factors there. We do not need this factor (especially because for our purpose the integral of the Gaussian bell must not always be 1) and thereforesimply leave it out.