Time-delay Neural Networks For Speech Recognition
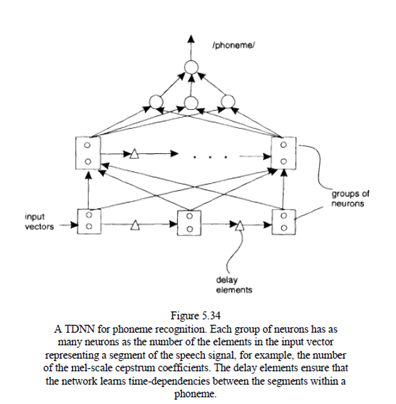
Time-delay neural networks (TDNNs) capture temporal speech information. Time-delay input frames allow the weights in the initial layers to account for time variations in speech. Like the MLP, they are feed forward networks. Figure shows a general TDNN scheme for the phoneme classification task. TDNNs are good at recognition of sub word units from continuous speech. For the recognition of continuous speech, a higher-level parsing framework is required in addition. It was discovered that a single monolithic TDNN was impractical for recognizing all the phonemes in Japanese. It was then suggested that a modular TDNN be used.
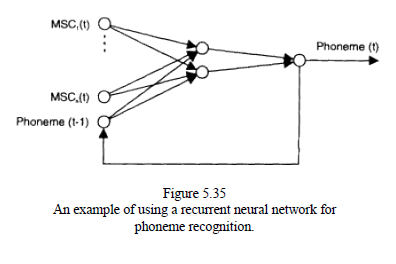
Recurrent Neural Networks for Speech Recognition
Recurrent neural networks, like the TDNNs, account for temporal variations in speech. A feedback loop connects the output nodes to the input nodes which makes them capable of encoding and recognizing sequential speech structures. The network can learn temporal dependencies from the speech sequences used for training. The recurrent networks are good for recognition of short isolated speech units. Owing to their structure they include some kind of time-warping effect. For continuous speech recognition, however, the recurrent neural networks must be used within some hybrid system.